A general way in how startups grow that most of us would have experienced first-hand is that we start with a monolith, and then as we scale to more and more businesses, we move to microservice architecture and start with platform thinking which helps avoid redundant work and encourages long-term, collaborative thinking.
Same is the case here at Ninjacart, since the end of 2021, an AgriTech company focused on Supply chain automation, which hassince expanded into Credit and Commerce verticals. And as we ventured into the different verticals, we took a step back and brought Platform thinking into our cognitive arsenal.
As we are experimenting, we often start with manual processes and then move into automating redundant tasks. At the time of introduction of Credit as a business, Limit setting for a single application took anywhere between 7-21 days. This was primarily attributed to delays in document collection due to availability of the customer / coapplicant or otherwise. We then streamlined this into a easy to use onboarding flow which reduced this timeline to 2-4 days at max.
We began by profiling the roles involved in the credit risk process to understand their workflows and identify manual, repetitive tasks that are prone to errors. Our goal was to automate these tasks through the introduction of Agentic AI. However, before diving into full-scale Agentic AI implementation, we focused on first establishing the foundational building blocks necessary to support such automation.
Our approach
As any good engineer would approach a complex problem, we broke it down into parallelizable building blocks to help achievethe overall goal as efficiently as possible.
The following are the 3 building blocks that we consider very important
1, Knowledge Graph with KGE (Knowledge Graph Embedding) support
2, Aventra – A search and retrieval system
3, Rule Book
Knowledge Graph with KGE support
A
Knowledge Graph (KG)
is a structured representation of real-world entities (e.g., borrowers, retailers, resellers, farmers)and the relationships between them. Unlike traditional relational databases, which store data in disconnected tables, a knowledge graph organizes information as an interconnected network of entities and relationships. This structure enables systems to better understand context, draw inferences, and support intelligent decision-making.
The objective was to identify direct relationships using the Knowledge Graph (KG), while leveraging Knowledge Graph Embeddings (KGE) to uncover indirect or latent relationships not explicitly represented in the graph. We are making use of the existing component of 2 years – NAO inspired by TAO, which helps us define the associations of any entity as a triple for KG and added KGE support with the help of Pykeen.
In the context of Credit Risk, we intend to use KG with KGE in 2 applications:
1, Borrower 360 – Provides a comprehensive, 360-degree view of each borrower by linking identifiers (PAN, phone, address, UPI, etc.) to behaviors, relationships, and risk signals.
2, Fraud Management – Detects suspicious user behavior like Device fraud, account fraud, collusion networks, identity sharing, and fraud rings through shared or inferred relationships.
Aventra - A search & retrieval system
For an AI model to be useful in specific contexts, it often needs access to background knowledge. For example, customer support chatbots need knowledge about the specific business they're being used for, and legal analyst bots need to know about a vast array of past cases.
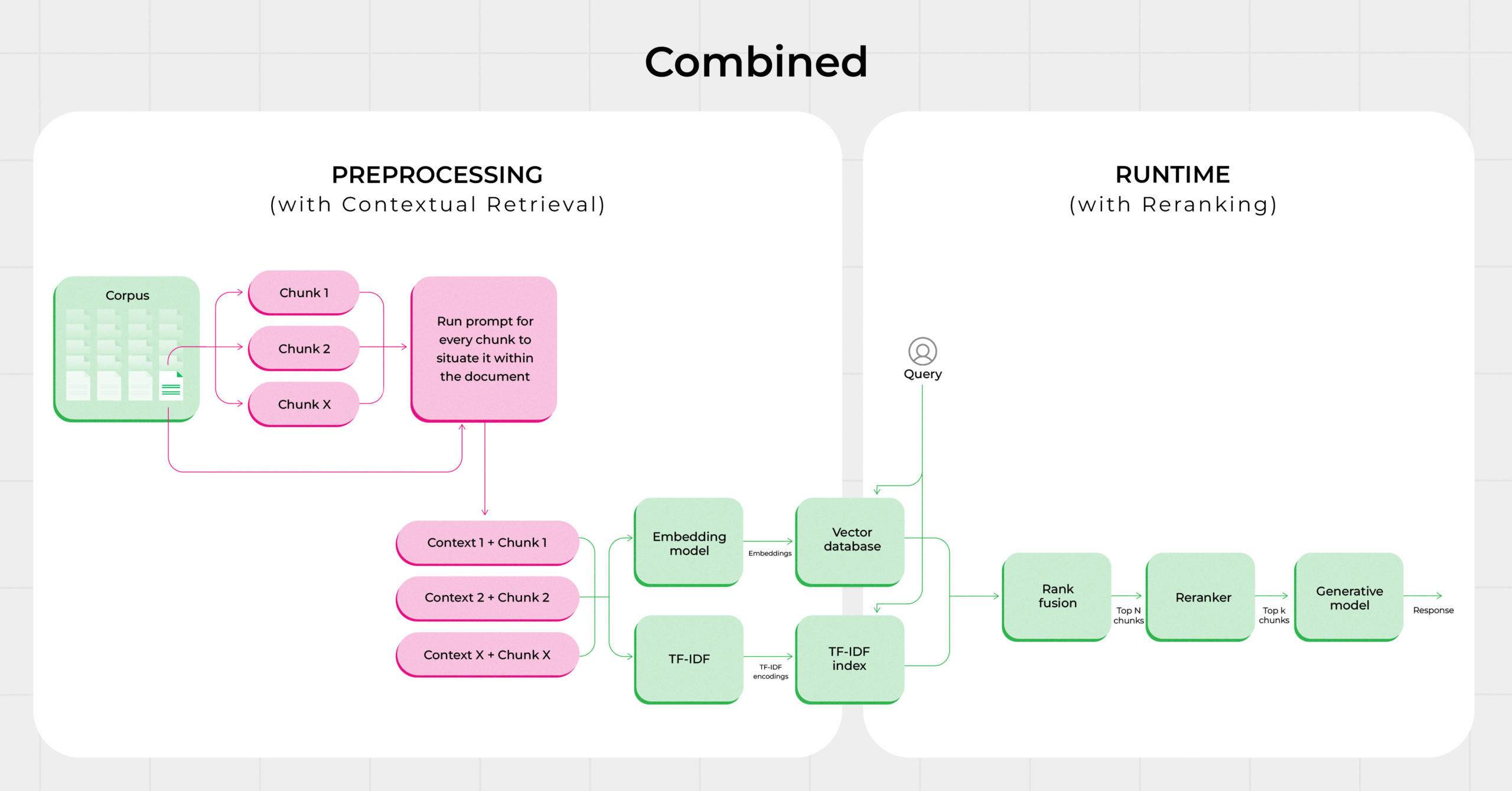
For the same, we have built a platform component called Aventra – which is an abstraction layer designed to unify and streamline the implementation of semantic search and retrieval systems. This component integrates multiple retrieval techniques including Haystack, RAG (Retrieval-Augmented Generation), BM25, Contextual Retrieval, and Knowledge Graph Embeddings (KGE) under a single interface. It uses PGVECT (PostgreSQL with vector extension support) as the backend for storing and querying dense vector embeddings.
In Credit business, we are intending to make use of this for FAQs that can help solve many repetitive tickets for the CX team.
Rule Book
The RuleBook Service is a Node.js-based microservice designed to manage and expose complex, dynamic lending rules, such as Lender Selection Rules, Eligibility Criteria, and other business-specific logic. It serves as a centralized rule configuration and evaluation engine, enabling real-time, rule-driven decisions across the User DataBunker ecosystem.
Rules are defined in a modular and extensible format and can be configured via secure administrative APIs. Once published, these rules are exposed as tools via the Model Context Protocol (MCP), making them directly consumable by AI agents. This allows intelligent systems to evaluate and apply lender-specific or context-driven logic in real time during user interactions or automated workflows.
In this part, we saw the 3 platform components that were introduced to start our journey on Agentic AI in Ninjacart. In the next part, we’ll see how we made use of our existing services using MCP, what were the models that were used in our Agentic AI and finally a glimpse of the architecture for the same
Future Use Cases
Building platform components is for making using of it in the near future for other business use cases. These platform components can be used in many places like:
1, Knowledge Graph can be used in Fraud Management for Commerce business
2, Aventra can be used in FAQ system in Kisaan ecosystem
3, Rule Book can be used in Disbursal eligibility in Credit Business






No Comment! Be the first one.